[Blog] Critical System Failure using Request Life Cycle: A Short Overview
Critical Systems Failure is a phrase that even the most experienced IT
professionals do not want to hear. Imagine your first day as an IT
engineer with your team, and a file server storing all your critical data has crashed. How would you and your team react? Of course, there were Disaster Recovery arrangements in place and you have hopes of getting it online with the least overhead cost to the business.
However, who
has the authorization to execute the DR plans? Who has the permissions and skill set to carry out the tasks? And who has the knowledge to understand the impact on other systems and perform preventive tasks on them?
The answers to these questions are essential in determining how quickly a team can respond to a critical system failure. And the efficiency of the response shouldn’t be left to the mercy of the experience of the team simply because there are always going to be new members on board and tenured people retiring.
Therefore,
the only logical conclusion is to have a process cycle of such a
Critical System Failure mapped structurally. And that is what we will be
discussing how to achieve using Request Life Cycle in ServiceDesk
Plus today.
RLC as we fondly like to call it, is a
diagrammatic approach more what status to what status a ticket has to
move from. This creates a structured approach of what must be done at each stage of the request. We can conditionally determine the
prerequisites of status before it can move to next, and also trigger
an action/executor when the status change happens.
The simple and straightforward benefits of using RLC:
- To provide a skeletal -standard operating procedure for the process.
- It allows us to show what is the next action required to be taken as per the SOP.
- This allows everyone, new employees included, to know exactly what needs to be done and when.
- With
fields and conditional mapping, we can also trigger actions such as approval, or sending notification in each step. Therefore keeping all the right persons notified.
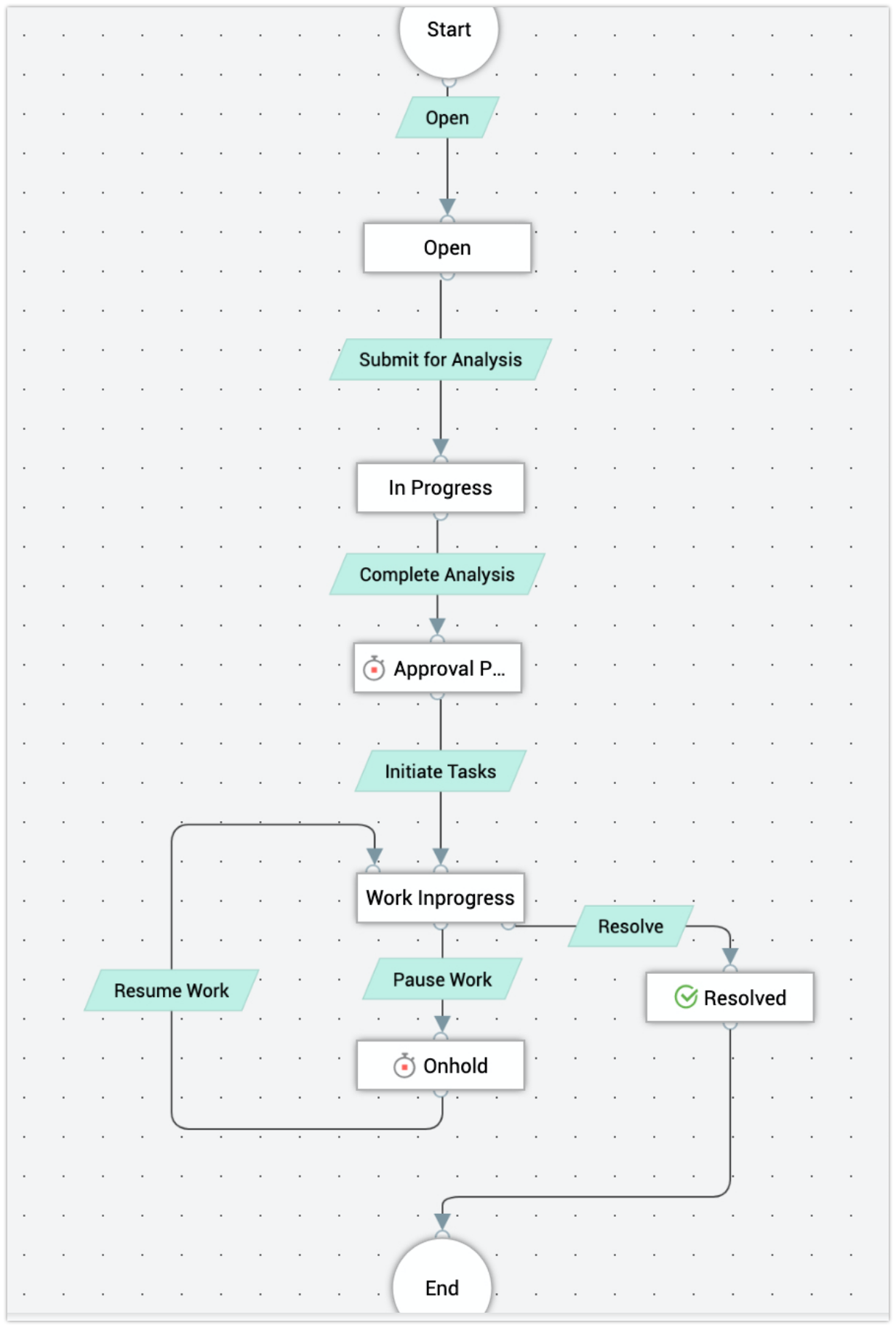
The more you customize and set up effective RLCs, the more rewards you can reap out of it. Please refer to the footer for an example RLC setup for simple and straightforward critical incident reporting.
I would like you to take note of how simple the flow is. And that the flow is linear in nature.
This clearly tells the technician working on the ticket that the ticket next
has
to be submitted for analysis. You can add multiple tasks within the request for your point of failure analysis, for immediate systems impacted analysis, recovery processes. And all of these can be triggered
using Field and Form Rules and RLC as a smooth workflow in the
ServiceDesk Plus.
Do you want to set up a notification once the initial analysis is done?
We got you covered!
Simply set up an After status completion action as shown. We can select a
notification template, users to be notified and set up a notification
directly from within the RLC!
And once the analysis is done, we can even execute a custom external script as well, to perform a server side action.
Here we have executed a python script that checks for Department
affected, Category, Subcategory and even some additional fields such as
City and Area.
And triggers a conditional approval, setting the request’s approver to be someone based on the above criteria.
To
facilitate this, an interesting thing to note is that these fields have
been made mandatory only in this stage, and not before that!
And lastly, a uniquely interesting feature is to be able to set up process loops in your procedure!
If you notice, the technician can never place this ticket on hold,
until the final stages. And once he gets to Work In-progress, the tech can either place it on hold or resolve a ticket!
Once all your work is completed, you can follow the flow and resolve the ticket. The depth and the variety of process workflows that you can
define are really limitless and left to your imagination.
We
have witnessed our users use RLC for creating workflows for User
On-boarding/Off-boarding, Old-Server Retirement, Server Patch Management,
Quick Fix Issues to even complex issue analysis processes.
What you get to do is lay down procedure maps for your users to follow based on scenarios. That, in turn, ensures that everyone always knows what to do and that is in accordance with the best practices!
What you get to do is lay down procedure maps for your users to follow based on scenarios. That, in turn, ensures that everyone always knows what to do and that is in accordance with the best practices!
The
procedures defined and followed by an organization is a mirror that
depicts the organization’s work culture and it’s seriousness towards
handling operations. The Request Life Cycle is a simple approach to
reducing chaos in everyday operations by offering a simple workflow for
users to adhere to.
We briefly exhibited how we can use the
Request Life Cycle for a Critical System Failure during everyday
operations or even Disaster Recovery events by showing how we can
configure workflow and conditional events around the workflow. We
leave the rest to your imagination and we are extremely happy to take
any questions for the same!
Let us try to simplify everyone’s lives even if it involves a bit of complexity in our own!
FOOTER:
Check our previous blog on Search Engine Optimization.
